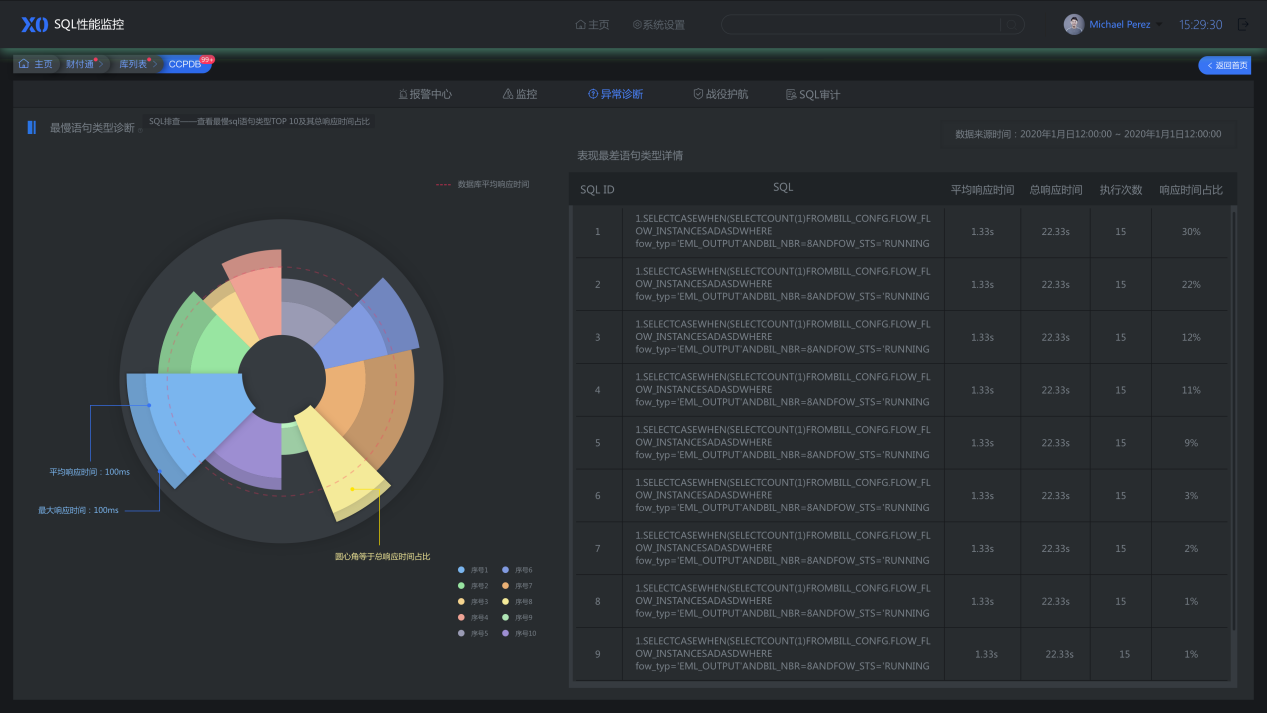
随着IT应用的快速发展,金融,银行,政府等越来越多的用户要求核心业务7*24不断网,不断电持续运行,进而出现了两地三中心的方案,是一些大型企业因为大自然的灾害而在同城选择两个机房异地选择一个机房而组成的称两地三中心,这样的方案具备高可用和灾难备份能力。
多中心应急灾难仿真演练方案
仿真测试
随着IT应用的快速发展,金融,银行,政府等越来越多的用户要求核心业务7*24不断网,不断电持续运行,进而出现了两地三中心的方案,是一些大型企业因为大自然的灾害而在同城选择两个机房异地选择一个机房而组成的称两地三中心,这样的方案具备高可用和灾难备份能力。
多中心应急灾难仿真演练方案
仿真测试
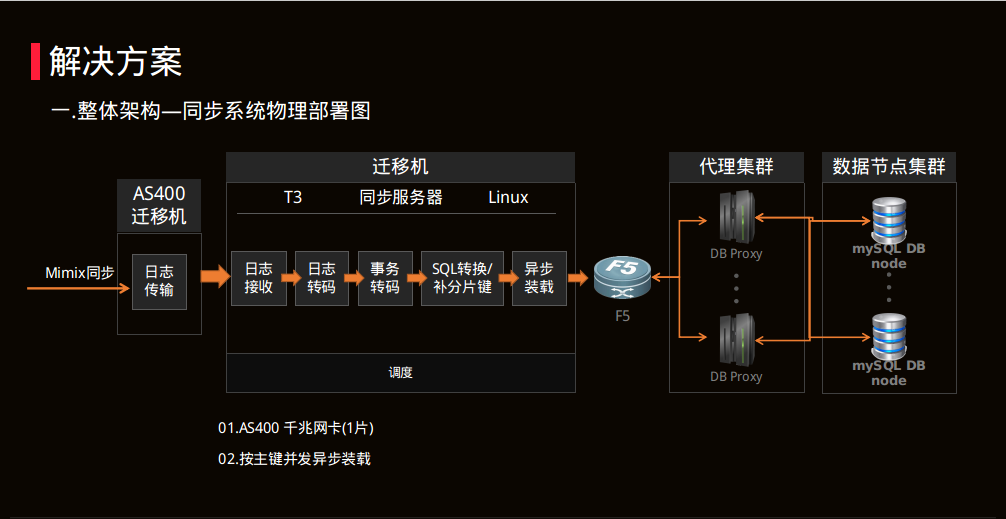
解决方案
 解决领域方案
迁移
仿真测试
版本升级
云集中监控
DB下移
容灾备份
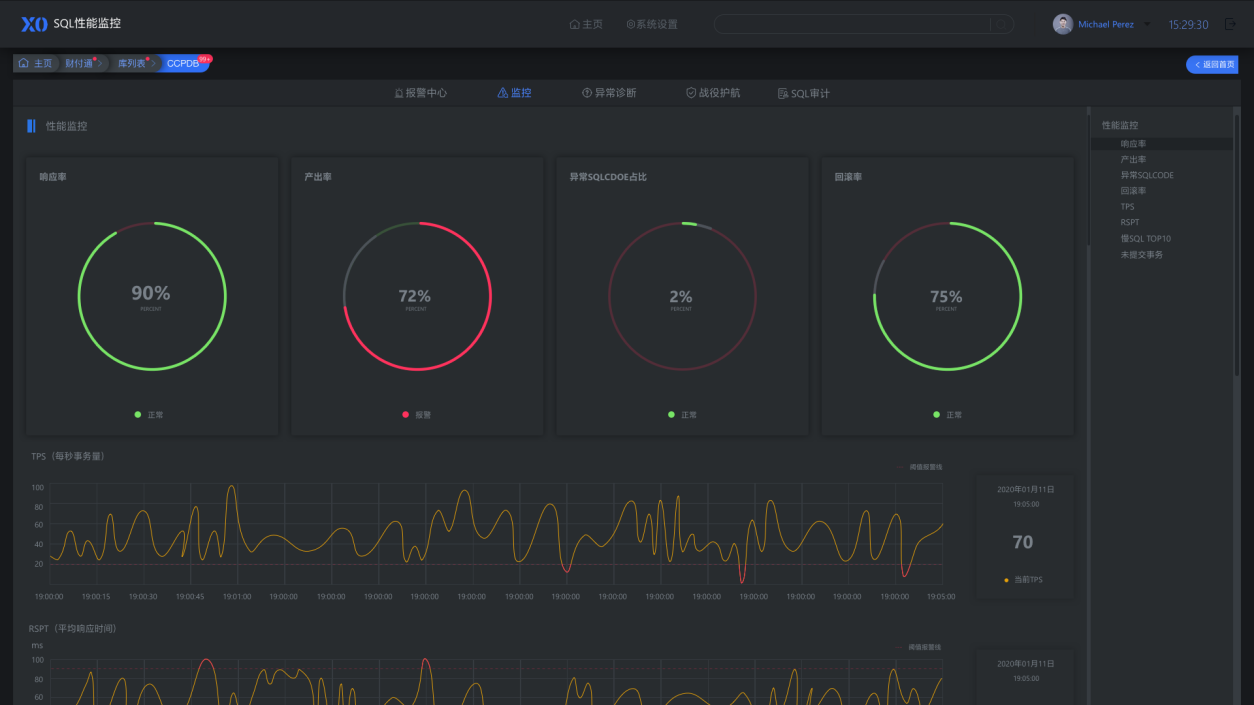
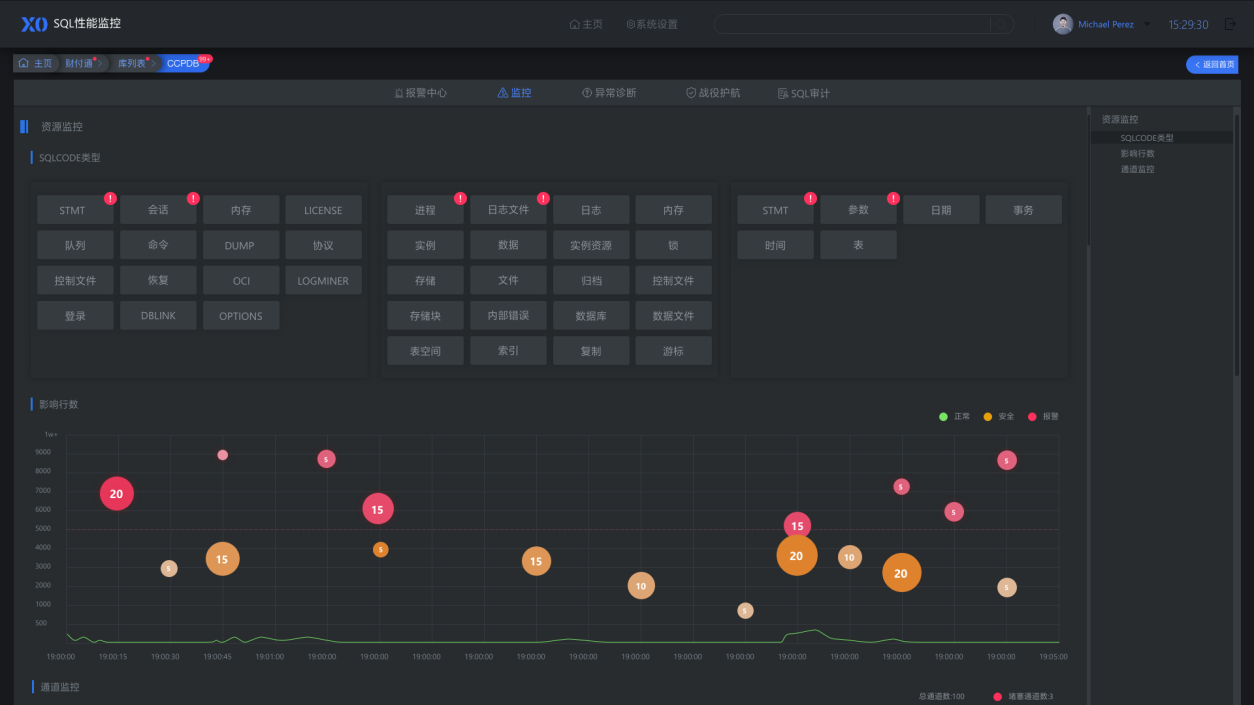
性能监控诊断
解决领域方案
迁移
仿真测试
版本升级
云集中监控
DB下移
容灾备份
性能监控诊断
首页
解决领域方案
迁移
仿真测试
版本升级
云集中监控
DB下移
容灾备份
性能监控诊断
产品介绍
0系列
透视诊断系列
1系列
3系列
迁移比对系列
云平台
了解更多


沃信推文
关于我们
0755-85219803
新闻动态
公司新闻
产品动态
专栏
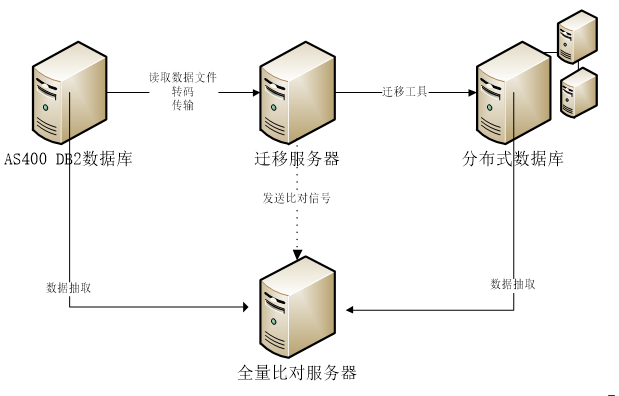
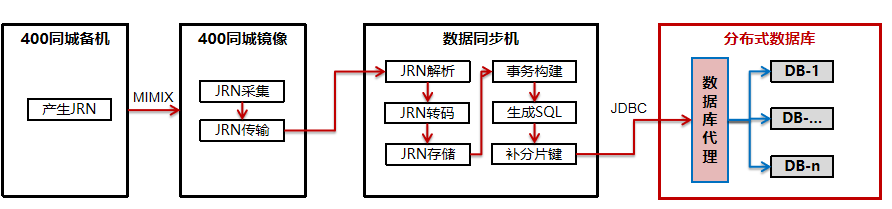
数据库迁移
主机下移
简体中文 English
English

用户有哪些需求
结合近年国内出现大范围自然灾害,以同城双中心加异地灾备中心的“两地三中心”的灾备模式也随之出现,这一方案兼具高可用性和灾难备份能力。但目前暂无相关工具可对其功能进行验证,所以急需一款既可真实模拟业务场景,又可以驱动灾难演练的工具。

了解技术方案
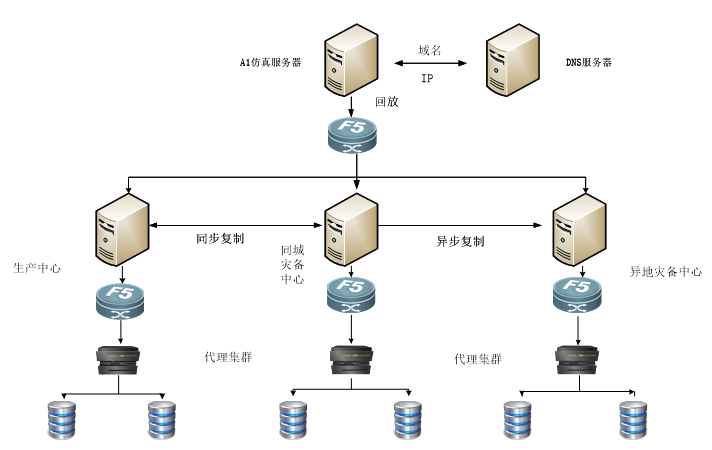

真实业务场景
业务流量重放,交易还原,实景再现

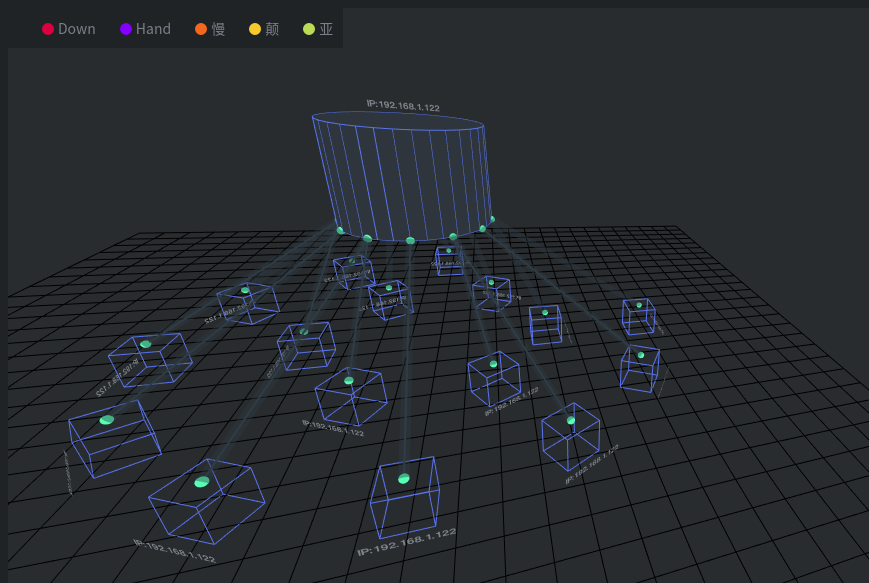
一键仿真
仿真全流程一键部署、启动、可容器化,大大提高演练有效性、可操作性;

水平扩展
可根据演练需求,实现快速扩展落地部署,达到高性能、高质量演练效果;

通过加压回放,可对三中心进行应用的性能测试;

提高切换演练效率
通过自动化仿真交易回放,可随时进行切换演练,减少演练前期的准备工作和人员投入;

简单高效
便捷的统一管理平台,WEB可视化界面,减少运维成本;